TL;DR
A Vec<T> consists of three values:
- A pointer to the heap-allocated buffer for the elements, which is created and owned by the
Vec<T>; - The number of elements that buffer has the capacity to store;
- A vector’s
capacitymethod returns returns the number of elements it could hold without reallocation.
- A vector’s
- The number it actually contains now (its length);
A String has a resizable buffer holding UTF-8 text. The buffer is allocated on the heap, so it can resize its buffer as needed or requested. You can think of a String as a Vec<u8> that is guaranteed to hold well-formed UTF-8; in fact, this is how String is implemented.
A slice, written [T] without specifying the length, is a region of an array or vector. Since a slice, which is a region of an array or vector by definition, can be any length, slices can’t be stored directly in variables or passed as function arguments. Slices are always passed by reference.
A reference to a slice is a fat pointer: a two-word value comprising a pointer to the slice’s first element, and the number of elements in the slice.
The str type, also called a ‘string slice’, is the most primitive string type. Like other slice references, a &str is a fat pointer, containing both the address of the actual data and its length. You can think of a &str as being nothing more than a &[u8] that is guaranteed to hold well-formed UTF-8.
A string literal is a &str that refers to preallocated text, typically stored in read-only memory (in the executable) along with the program’s machine code.
&str is very much like &[T]: a fat pointer to some data. String is analogous to Vec<T>.
Implicit conversions:
Rust implicitly produces a
&mut [i32]slice referring to the entire array and passes that tosortto operate on.1 2 3let mut chaos = [3, 5, 4, 1, 2]; chaos.sort(); assert_eq!(chaos, [1, 2, 3, 4, 5]);The
reversemethod is actually defined on slices, but the call implicitly borrows a&mut [&str]slice from the vector and invokesreverseon that.1 2 3let mut palindrome = vec!["a man", "a plan", "a canal", "panama"]; palindrome.reverse(); assert_eq!(palindrome, vec!["panama", "a canal", "a plan", "a man"]);
zero-tuple () is a commonly used tuple type. It’s traditionally called the unit type because it has only one value, also written (). Rust uses the unit type where there’s no meaningful value to carry, but context requires some sort of type nonetheless. A function that returns no value has a return type of ().
| |
Brief
Rust lets developers choose the data representation that best fits the situation, with the right balance between simplicity and cost. Rust’s fundamental types for representing values have concrete machine-level counterparts with predictable costs and performance.
- Although Rust doesn’t promise it will represent things exactly as you’ve requested, it takes care to deviate from your requests only when it’s a reliable improvement.
Given the types that you do spell out, Rust’s type inference will figure out most of the rest for you. In practice, there’s often only one type that will work for a given variable or expression; when this is the case, Rust lets you leave out, or elide, the type. Type inference gives back much of the legibility of dynamically typed languages, while still catching type errors at compile time.
| |
- These two definitions are exactly equivalent, and Rust will generate the same machine code either way.
Rust functions can be generic: a single function can work on values of many different types. Rust’s generic functions give the language a degree of flexibility, while still catching all type errors at compile time.
- Despite their flexibility, generic functions are just as efficient as their nongeneric counterparts. There is no inherent performance advantage to be had from writing, say, a specific sum function for each integer over writing a generic one that handles all integers.
Fixed-Width Numeric Types
The footing of Rust’s type system is a collection of fixed-width numeric types, chosen to match the types that almost all modern processors implement directly in hardware.
Fixed-width numeric types can overflow or lose precision, but they are adequate for most applications and can be thousands of times faster than representations like arbitrary-precision integers and exact rationals.
- The rational numbers are the set of all numbers that can be written as fractions
p/q, wherepandqare integers.
| Size (bits) | Unsigned integer | Signed integer | Floating-point |
|---|---|---|---|
| 8 | u8 | i8 | |
| 16 | u16 | i16 | |
| 32 | u32 | i32 | f32 |
| 64 | u64 | i64 | f64 |
| 128 | u128 | i128 | |
| Machine word | usize | isize |
- A machine word is a value equal in size to the address space of the machine on which the code runs: it is 32 bits long on 32-bit architectures and 64 bits long on 64-bit architectures.
Integer Types
Rust’s unsigned integer types use their full range to represent positive values and zero.
Rust’s signed integer types use the two’s complement representation, using the same bit patterns as the corresponding unsigned type to cover a range of positive and negative values.
Rust uses the u8 type for byte values.
Rust treats characters as distinct from the numeric types: a char is not a u8, nor is it a u32 (though it is 32 bits long).
The usize and isize types are analogous to size_t and ptrdiff_t in C and C++. Their precision matches the size of the address space on the target machine: they are 32 bits long on 32-bit architectures, and 64 bits long on 64-bit architectures. Rust requires array indices to be usize values. Values representing the sizes of arrays or vectors or counts of the number of elements in some data structure also generally have the usize type.
Integer literals in Rust can take a suffix indicating their type: 42u8 is a u8 value; 1729isize is an isize. If an integer literal lacks a type suffix, Rust puts off determining its type until it finds the value being used in a way that pins it down: stored in a variable of a particular type, passed to a function that expects a particular type, compared with another value of a particular type, or something like that. In the end, if multiple types could work, Rust defaults to i32 if that is among the possibilities. Otherwise, Rust reports the ambiguity as an error.
| |
- Although all the signed integer types have an
absmethod, for technical reasons, Rust wants to know exactly which integer type a value has before it will call the type’s own methods. The default ofi32applies only if the type is still ambiguous after all method calls have been resolved, so that’s too late to help here.
The prefixes 0x, 0o, and 0b designate hexadecimal, octal, and binary literals.
To make long numbers more legible, you can insert underscores among the digits. The exact placement of the underscores is not significant.
4_294_967_295;0xffff_ffff;127_u8.
Although numeric types and the char type are distinct, Rust does provide byte literals, character-like literals for u8 values. Only ASCII characters may appear in byte literals. Byte literals are just another notation for u8 values.
b'A'represents the ASCII code for the characterA, as au8value. Since the ASCII code forAis 65, the literalsb'A'and65u8are exactly equivalent.
There are a few characters that you cannot simply place after the single quote, because that would be either syntactically ambiguous or hard to read. These characters can only be written using a stand-in notation, introduced by a backslash.
| Character | Byte literal | Numeric equivalent |
|---|---|---|
Single quote, ' | b'\'' | 39u8 |
Backslash, \ | b'\\' | 92u8 |
| Newline | b'\n' | 10u8 |
| Carriage return | b'\r' | 13u8 |
| Tab | b'\t' | 9u8 |
For characters that are hard to write or read, you can write their code in hexadecimal instead. A byte literal of the form b'\xHH', where HH is any two-digit hexadecimal number, represents the byte whose value is HH.
- You can write a byte literal for the ASCII “escape” control character as
b'\x1b', since the ASCII code for “escape” is 27, or 1B in hexadecimal. Since byte literals are just another notation foru8values, consider whether a simple numeric literal might be more legible: it probably makes sense to useb'\x1b'instead of simply27only when you want to emphasize that the value represents an ASCII code.
Convert from one integer type to another using the as operator.
| |
The standard library provides some operations as methods on integers. For example:
| |
Checked, Wrapping, Saturating, and Overflowing Arithmetic
When an integer arithmetic operation overflows, Rust panics, in a debug build. In a release build, the operation* wraps around*: it produces the value equivalent to the mathematically correct result modulo the range of the value (truncation). (In neither case is overflow undefined behavior, as it is in C and C++.)
| |
The integer types provide methods to override default overflow behaviors.
| |
These integer arithmetic methods fall in 4 general categories:
Checked operations return an
Optionof the result:Some(v)if the mathematically correct result can be represented as a value of that type, orNoneif it cannot.1 2 3 4 5 6 7 8assert_eq!(10_u8.checked_add(20), Some(30)); // ok assert_eq!(100_u8.checked_add(200), None); // overflow // Do the addition; panic if it overflows. let sum = x.checked_add(y).unwrap(); // Panics if the self value equals [`None`]. // Oddly, signed division can overflow too, in one particular case. // A signed n-bit type can represent -2ⁿ⁻¹, but not 2ⁿ⁻¹. assert_eq!((-128_i8).checked_div(-1), None);Wrapping operations return the value equivalent to the mathematically correct result modulo the range of the value (truncation).
1 2 3 4 5 6 7 8 9 10 11assert_eq!(100_u16.wrapping_mul(200), 20000); // no truncation assert_eq!(500_u16.wrapping_mul(500), 53392); // 250000 modulo 2¹⁶ // Operations on signed types may wrap to negative values. assert_eq!(500_i16.wrapping_mul(500), -12144); // In bitwise shift operations, the shift distance // is wrapped to fall within the size of the value. // So a shift of 17 bits in a 16-bit type is a shift // of 1. assert_eq!(5_i16.wrapping_shl(17), 10);Saturating operations return the representable value that is closest to the mathematically correct result. The result is “clamped” to the maximum and minimum values the type can represent.
1 2assert_eq!(32760_i16.saturating_add(10), 32767); assert_eq!((-32760_i16).saturating_sub(10), -32768);- There are no saturating division, remainder, or bitwise shift methods.
Overflowing operations return a tuple
(result, overflowed), whereresultis what the wrapping version of the function would return, andoverflowedis a bool indicating whether an overflow occurred.1 2 3 4 5assert_eq!(255_u8.overflowing_sub(2), (253, false)); assert_eq!(255_u8.overflowing_add(2), (1, true)); // A shift of 17 bits is too large for `u16`, and 17 modulo 16 is 1. assert_eq!(5_u16.overflowing_shl(17), (10, true));overflowing_shlandoverflowing_shrreturn true foroverflowedonly if the shift distance was as large or larger than the bit width of the type itself. The actual shift applied is the requested shift modulo the bit width of the type.
Floating-Point Types
Rust provides IEEE single- and double-precision floating-point types. These types include positive and negative infinities (INFINITY, NEG_INFINITY), distinct positive and negative zero values, and a not-a-number (NAN) value.
| Type | Precision | Range |
|---|---|---|
f32 | IEEE single precision (at least 6 decimal digits) | Roughly $$–3.4 × 10^{38}$$ to $$+3.4 × 10^{38}$$ |
f64 | IEEE double precision (at least 15 decimal digits) | Roughly $$–1.8 × 10^{308}$$ to $$+1.8 × 10^{308}$$ |
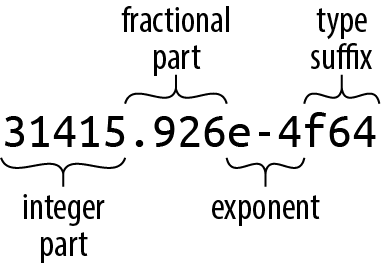
Every part of a floating-point number after the integer part is optional, but at least one of the fractional part, exponent, or type suffix must be present, to distinguish it from an integer literal. The fractional part may consist of a lone decimal point, so 5. is a valid floating-point constant.
If a floating-point literal lacks a type suffix, Rust checks the context to see how the values are used, much as it does for integer literals. If it ultimately finds that either floating-point type could fit, it chooses f64 by default.
For the purposes of type inference, Rust treats integer literals and floating-point literals as distinct classes: it will never infer a floating-point type for an integer literal, or vice versa.
As with integers, you usually won’t need to write out type suffixes on floating-point literals in real code, but when you do, putting a type on either the literal or the function will suffice:
| |
Unlike C and C++, Rust performs almost no numeric conversions implicitly. Implicit integer conversions have a well-established record of causing bugs and security holes, especially when the integers in question represent the size of something in memory, and an unanticipated overflow occurs.
The bool Type
Rust’s Boolean type, bool, has the usual two values for such types, true and false.
Control structures like if and while require their conditions to be bool expressions, as do the short-circuiting logical operators && and ||.
Rust’s as operator can convert bool values to integer types:
| |
However, as won’t convert in the other direction, from numeric types to bool. You must write out an explicit comparison like x != 0.
Although a bool needs only a single bit to represent it, Rust uses an entire byte for a bool value in memory, so you can create a pointer to it.
- 内存单元的大小是 1 byte。
Characters
Rust’s character type char represents a single Unicode character, as a 32-bit value.
Rust uses the char type for single characters in isolation, but uses the UTF-8 encoding for strings and streams of text. So, a String represents its text as a sequence of UTF-8 bytes, not as an array of characters.
Character literals are characters enclosed in single quotes, like '8' or '!'.
Characters that require backslash escapes:
| Character | Rust character literal |
|---|---|
Single quote, ' | '\'' |
Backslash, \ | '\\' |
| Newline | '\n' |
| Carriage return | '\r' |
| Tab | '\t' |
If you prefer, you, can write out a character’s Unicode code point in hexadecimal:
- If the character’s code point is in the range
U+0000toU+007F(that is, if it is drawn from the ASCII character set), then you can write the character as'\xHH', whereHHis a two-digit hexadecimal number.- The character literals
'*'and'\x2A'are equivalent, because the code point of the character*is 42, or 2A in hexadecimal.
- The character literals
- You can write any Unicode character as
'\u{HHHHHH}', whereHHHHHHis a hexadecimal number up to six digits long, with underscores allowed for grouping as usual.
A char always holds a Unicode code point in the range 0x0000 to 0xD7FF, or 0xE000 to 0x10FFFF. A char is never a surrogate pair half (that is, a code point in the range 0xD800 to 0xDFFF), or a value outside the Unicode codespace (that is, greater than 0x10FFFF). Rust uses the type system and dynamic checks to ensure char values are always in the permitted range.
Rust never implicitly converts between char and any other type. You can use the as conversion operator to convert a char to an integer type; for types smaller than 32 bits, the upper bits of the character’s value are truncated.
| |
u8 is the only type the as operator will convert to char. Rust intends the as operator to perform only cheap, infallible conversions, but every integer type other than u8 includes values that are not permitted Unicode code points, so those conversions would require run-time checks. Instead, the standard library function std::char::from_u32 takes any u32 value and returns an Option<char>: if the u32 is not a permitted Unicode code point, then from_u32 returns None; otherwise, it returns Some(c), where c is the char result.
Tuples
A tuple is a pair, or triple, quadruple, quintuple, etc. (hence, n-tuple, or tuple), of values of assorted types.
You can write a tuple as a sequence of elements, separated by commas and surrounded by parentheses.
("Brazil", 1985)(&str, i32)
Given a tuple value
t, you can access its elements ast.0,t.1, and so on.Rust code often uses tuple types to return multiple values from a function.
1 2 3 4 5 6 7 8 9 10 11fn split_at(&self, mid: usize) -> (&str, &str); let text = "I see the eigenvalue in thine eye"; // * use pattern-matching syntax to assign each element of the return value to a different variable let (head, tail) = text.split_at(21); assert_eq!(head, "I see the eigenvalue "); assert_eq!(tail, "in thine eye"); // less legible let temp = text.split_at(21); let head = temp.0; let tail = temp.1;
Although both tuples and arrays represent an ordered sequence of values, in Rust, they’re completely separate.
- Each element of a tuple can have a different type, whereas an array’s elements must be all the same type.
- Tuples allow only constants as indices, like
t.4. You can’t writet.iort[i]to get theith element.
Tuples can used as a sort of minimal-drama struct type.
| |
- The type of the
boundsparameter is(usize, usize), a tuple of twousizevalues. - We could just as well write out separate
widthandheightparameters, and the machine code would be about the same either way. It’s a matter of clarity. We think of the size as one value, not two, and using a tuple lets us write what we mean.- We could declare a struct with
widthandheightmembers, but that’s pretty heavy notation for something so obvious.
- We could declare a struct with
The other commonly used tuple type is the zero-tuple (). This is traditionally called the unit type because it has only one value, also written (). Rust uses the unit type where there’s no meaningful value to carry, but context requires some sort of type nonetheless.
A function that returns no value has a return type of
().1 2 3 4 5 6fn swap<T>(x: &mut T, y: &mut T); // shorthand for fn swap<T>(x: &mut T, y: &mut T) -> (); // returns a `std::io::Error` value if something goes wrong, but returns no value on success. fn write_image(filename: &str, pixels: &[u8], bounds: (usize, usize)) -> Result<(), std::io::Error>;
You may include a comma after a tuple’s last element. Rust consistently permits an extra trailing comma everywhere commas are used: function arguments, arrays, struct and enum definitions, and so on.
- For consistency’s sake, there are tuples that contain a single value. The literal
("lonely hearts",)is a tuple containing a single string; its type is(&str,). Here, the comma after the value is necessary to distinguish the singleton tuple from a simple parenthetic expression.
Pointer Types
Rust has several types that represent memory addresses.
This is a big difference between Rust and most languages with garbage collection. In Java, if class Rectangle contains a field Vector2D upperLeft;, then upperLeft is a reference to another separately created Vector2D object. Objects never physically contain other objects in Java.
Rust is different. It is designed to help keep allocations to a minimum. Values nest by default. The value ((0, 0), (1440, 900)) is stored as four adjacent integers. If you store it in a local variable, you’ve got a local variable four integers wide. Nothing is allocated in the heap.
This is great for memory efficiency, but as a consequence, when a Rust program needs values to point to other values, it must use pointer types explicitly.
References, boxes, and unsafe pointers are 3 pointer types.
References
A value of type &String (pronounced “ref String”) is a reference to a String value, a &i32 is a reference to an i32, and so on.
It’s easiest to get started by thinking of references as Rust’s basic pointer type. At run time, a reference to an i32 is a single machine word holding the address of the i32, which may be on the stack or in the heap.
The expression &x produces a reference to x; in Rust terminology, we say that it borrows a reference to x. Given a reference r, the expression *r refers to the value r points to.
- These are very much like the
&and*. operators in C and C++. Like a C pointer, a reference does not automatically free any resources when it goes out of scope.
Unlike C pointers, however, Rust references are never null: there is simply no way to produce a null reference in safe Rust. Rust tracks the ownership and lifetimes of values, so mistakes like dangling pointers, double frees, and pointer invalidation are ruled out at compile time.
Rust references come in 2 flavors:
&T: an immutable, shared reference.- You can have many shared references to a given value at a time, but they are read-only: modifying the value they point to is forbidden, as with
const T*in C.
- You can have many shared references to a given value at a time, but they are read-only: modifying the value they point to is forbidden, as with
&mut T: a mutable, exclusive reference.- You can read and modify the value it points to, as with a
T*in C. - For as long as the reference exists, you may not have any other references of any kind to that value. In fact, the only way you may access the value at all is through the mutable reference.
- You can read and modify the value it points to, as with a
Rust uses this dichotomy between shared and mutable references to enforce a “single writer or multiple readers” rule: either you can read and write the value, or it can be shared by any number of readers, but never both at the same time. This separation, enforced by compile-time checks, is central to Rust’s safety guarantees.
Boxes
The simplest way to allocate a value in the heap is to use Box::new.
| |
- The type of
tis(i32, &str), so the type ofbisBox<(i32, &str)>.Box::newallocates enough memory to contain the tuple on the heap. - When
bgoes out of scope, the memory is freed immediately, unlessbhas been moved—by returning it, for example.- Moves are essential to the way Rust handles heap-allocated values.
Boxes allow you to store data on the heap rather than the stack. What remains on the stack is the pointer to the heap data.
Boxes don’t have performance overhead, other than storing their data on the heap instead of on the stack. But they don’t have many extra capabilities either. You’ll use them most often in these situations:
- When you have a type whose size can’t be known at compile time and you want to use a value of that type in a context that requires an exact size
- When you have a large amount of data and you want to transfer ownership but ensure the data won’t be copied when you do so
- When you want to own a value and you care only that it’s a type that implements a particular trait rather than being of a specific type
The Stack and the Heap
Both the stack and the heap are parts of memory available to your code to use at runtime, but they are structured in different ways. The stack stores values in the order it gets them and removes the values in the opposite order. This is referred to as last in, first out. Think of a stack of plates: when you add more plates, you put them on top of the pile, and when you need a plate, you take one off the top. Adding or removing plates from the middle or bottom wouldn’t work as well! Adding data is called pushing onto the stack, and removing data is called popping off the stack. All data stored on the stack must have a known, fixed size. Data with an unknown size at compile time or a size that might change must be stored on the heap instead.
The heap is less organized: when you put data on the heap, you request a certain amount of space. The memory allocator finds an empty spot in the heap that is big enough, marks it as being in use, and returns a pointer, which is the address of that location. This process is called allocating on the heap and is sometimes abbreviated as just allocating (pushing values onto the stack is not considered allocating). Because the pointer to the heap is a known, fixed size, you can store the pointer on the stack, but when you want the actual data, you must follow the pointer. Think of being seated at a restaurant. When you enter, you state the number of people in your group, and the host finds an empty table that fits everyone and leads you there. If someone in your group comes late, they can ask where you’ve been seated to find you.
Pushing to the stack is faster than allocating on the heap because the allocator never has to search for a place to store new data; that location is always at the top of the stack. Comparatively, allocating space on the heap requires more work because the allocator must first find a big enough space to hold the data and then perform bookkeeping to prepare for the next allocation.
Accessing data in the heap is slower than accessing data on the stack because you have to follow a pointer to get there. Contemporary processors are faster if they jump around less in memory. Continuing the analogy, consider a server at a restaurant taking orders from many tables. It’s most efficient to get all the orders at one table before moving on to the next table. Taking an order from table A, then an order from table B, then one from A again, and then one from B again would be a much slower process. By the same token, a processor can do its job better if it works on data that’s close to other data (as it is on the stack) rather than farther away (as it can be on the heap).
When your code calls a function, the values passed into the function (including, potentially, pointers to data on the heap) and the function’s local variables get pushed onto the stack. When the function is over, those values get popped off the stack.
Keeping track of what parts of code are using what data on the heap, minimizing the amount of duplicate data on the heap, and cleaning up unused data on the heap so you don’t run out of space are all problems that ownership addresses. Knowing that the main purpose of ownership is to manage heap data can help explain why it works the way it does.
Raw Pointers
Rust has the raw pointer types *mut T and *const T. Raw pointers really are just like pointers in C++. Using a raw pointer is unsafe, because Rust makes no effort to track what it points to.
Raw pointers may be null, or they may point to memory that has been freed or that now contains a value of a different type.
You may only dereference raw pointers within an unsafe block. An unsafe block is Rust’s opt-in mechanism for advanced language features whose safety is up to you.
Arrays, Vectors, and Slices
Rust has 3 types for representing a sequence of values in memory:
- The type
[T; N]represents an array ofNvalues, each of typeT.- An array’s size is a constant determined at compile time and is part of the type; you can’t append new elements or shrink an array.
- The type
Vec<T>, called a vector ofTs, is a dynamically allocated (on heap), growable sequence of values of typeT.- A vector’s elements are allocated on the heap, so you can resize vectors at will: push new elements onto them, append other vectors to them, delete elements, and so on.
- The types
&[T]and&mut [T], called a shared slice ofTs and mutable slice ofTs, are references to a series of elements that are a part of some other value, like an array or vector.- You can think of a slice as a pointer to its first element, together with a count of the number of elements you can access starting at that point.
- A mutable slice
&mut [T]lets you read and modify elements, but can’t be shared; a shared slice&[T]lets you share access among several readers, but doesn’t let you modify elements.
Given a value v of any of these three types, the expression v.len() gives the number of elements in v, and v[i] refers to the ith element of v. The first element is v[0], and the last element is v[v.len() - 1].
- Rust checks that
ialways falls within this range; if it doesn’t, the expression panics. - The length of
vmay be zero, in which case any attempt to index it will panic. imust be ausizevalue; you can’t use any other integer type as an index.
Arrays
Write array values:
| |
[V; N]produces an array of lengthNfilled with valueV.[true; 10000]is an array of 10,000boolelements, all set totrue.[0u8; 1024]can be a one-kilobyte buffer, filled with zeros.
Rust has no notation for an uninitialized array. In general, Rust ensures that code can never access any sort of uninitialized value.
An array’s length is part of its type and fixed at compile time. If n is a variable, you can’t write [true; n] to get an array of n elements. When you need an array whose length varies at run time (and you usually do), use a vector instead.
The useful methods on arrays—iterating over elements, searching, sorting, filling, filtering, and so on—are all provided as methods on slices, not arrays. Rust implicitly converts an array to a slice when searching for methods, so you can call any slice method on an array directly:
| |
- Rust implicitly produces a
&mut [i32]slice referring to the entire array and passes that tosortto operate on. - The
lenmethod is a slice method as well.
Vectors
A vector Vec<T> is a resizable array of elements of type T, allocated on the heap.
Create vectors:
| |
- The
vec!macro is equivalent to callingVec::newto create a new, empty vector and then pushing the elements onto it, - You’ll often need to supply the type when using
collect, because it can build many different sorts of collections, not just vectors. By specifying the type ofv, we’ve made it unambiguous which sort of collection we want.
As with arrays, you can use slice methods on vectors.
| |
- The
reversemethod is actually defined on slices, but the call implicitly borrows a&mut [&str]slice from the vector and invokesreverseon that.
A Vec<T> consists of three values:
- A pointer to the heap-allocated buffer for the elements, which is created and owned by the
Vec<T>; - The number of elements that buffer has the capacity to store;
- A vector’s
capacitymethod returns returns the number of elements it could hold without reallocation.
- A vector’s
- The number it actually contains now (its length);
When the buffer has reached its capacity, adding another element to the vector entails allocating a larger buffer, copying the present contents into it, updating the vector’s pointer and capacity to describe the new buffer, and finally freeing the old one.
If you know the number of elements a vector will need in advance, instead of Vec::new you can call Vec::with_capacity to create a vector with a buffer large enough to hold them all, right from the start; then, you can add the elements to the vector one at a time without causing any reallocation.
- This only establishes the vector’s initial size; if you exceed your estimate, the vector simply enlarges its storage as usual.
- The
vec!macro uses a trick like this, since it knows how many elements the final vector will have.
The capacity method returns the number of elements it could hold without reallocation:
| |
Insert and remove elements:
| |
Use the pop method to remove the last element and return it.
| |
- Popping a value from a
Vec<T>returns anOption<T>:Noneif the vector was already empty, orSome(v)if its last element had beenv.
Use a for loop to iterate over a vector:
| |
Vec is an ordinary type defined in Rust, not built into the language.
Slices
A slice, written [T] without specifying the length, is a region of an array or vector. Since a slice can be any length, slices can’t be stored directly in variables or passed as function arguments. Slices are always passed by reference.
A reference to a slice is a fat pointer: a two-word value comprising a pointer to the slice’s first element, and the number of elements in the slice.
| |
In the last two lines, Rust automatically converts the
&Vec<f64>reference and the&[f64; 4]reference to slice references that point directly to the data. By the end, memory looks like this: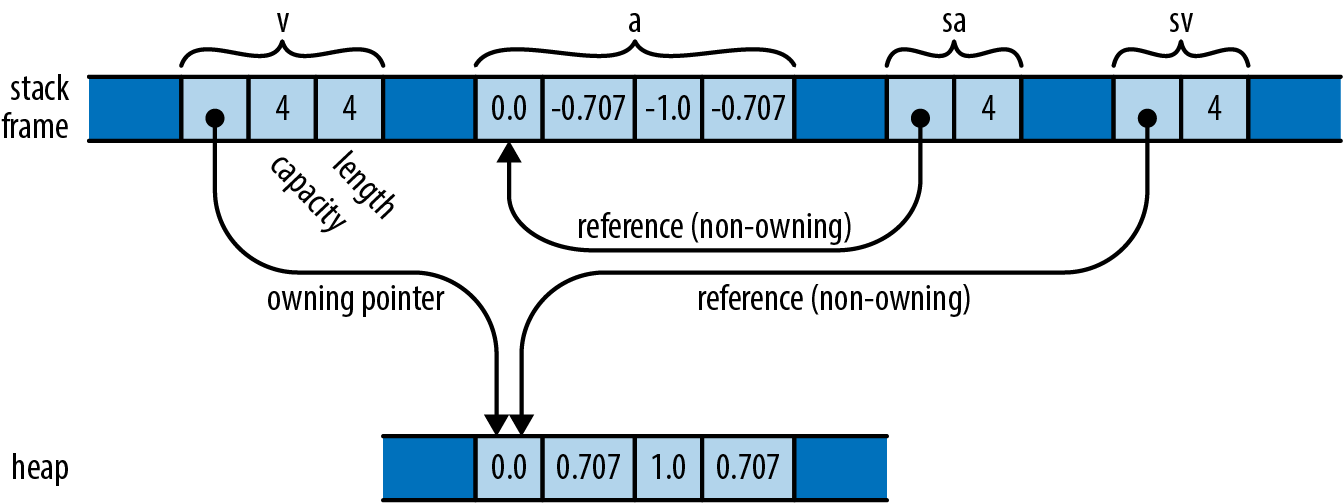
Whereas an ordinary reference is a non-owning pointer to a single value, a reference to a slice is a non-owning pointer to a range of consecutive values in memory. This makes slice references a good choice when you want to write a function that operates on either an array or a vector.
| |
You can get a reference to a slice of an array or vector, or a slice of an existing slice, by indexing it with a range.
| |
- As with ordinary array accesses, Rust checks that the indices are valid. Trying to borrow a slice that extends past the end of the data results in a panic.
Since slices almost always appear behind references, we often just refer to types like &[T] or &str as “slices,” using the shorter name for the more common concept.
String Types
In C++, there are two string types in the language. String literals have the pointer type const char *. The standard library also offers a class, std::string, for dynamically creating strings at run time. Rust has a similar design.
String Literals
String literals are enclosed in double quotes. They use the same backslash escape sequences as char literals.
A string may span multiple lines.
| |
- The newline character in that string literal is included in the string and therefore in the output. So are the spaces at the beginning of the second line.
If one line of a string ends with a backslash, then the newline character and the leading whitespace on the next line are dropped.
| |
In a few cases, the need to double every backslash in a string is a nuisance. For these cases, Rust offers raw strings. A raw string is tagged with the lowercase letter r. All backslashes and whitespace characters inside a raw string are included verbatim in the string. No escape sequences are recognized.
| |
You can’t include a double-quote character in a raw string simply by putting a backslash in front of it—remember, we said no escape sequences are recognized. However, there is a cure for that too. The start and end of a raw string can be marked with pound signs:
1 2 3 4 5println!(r###" This raw string started with 'r###"'. Therefore it does not end until we reach a quote mark ('"') followed immediately by three pound signs ('###'): "###);You can add as few or as many pound signs as needed to make it clear where the raw string ends.
Byte Strings
A string literal with the b prefix is a byte string. Such a string is a slice of u8 values—that is, bytes—rather than Unicode text.
| |
- The type of
methodis&[u8; 3]. It’s a reference to an array of three bytes.
Byte strings can span multiple lines, use escape sequences, and use backslashes to join lines. Raw byte strings start with br".
Byte strings can’t contain arbitrary Unicode characters. They must make do with ASCII and \xHH escape sequences.
Strings in Memory
Rust strings are sequences of Unicode characters, but they are not stored in memory as arrays of chars. Instead, they are stored using UTF-8, a variable-width encoding. Each ASCII character in a string is stored in one byte. Other characters take up multiple bytes.
| |
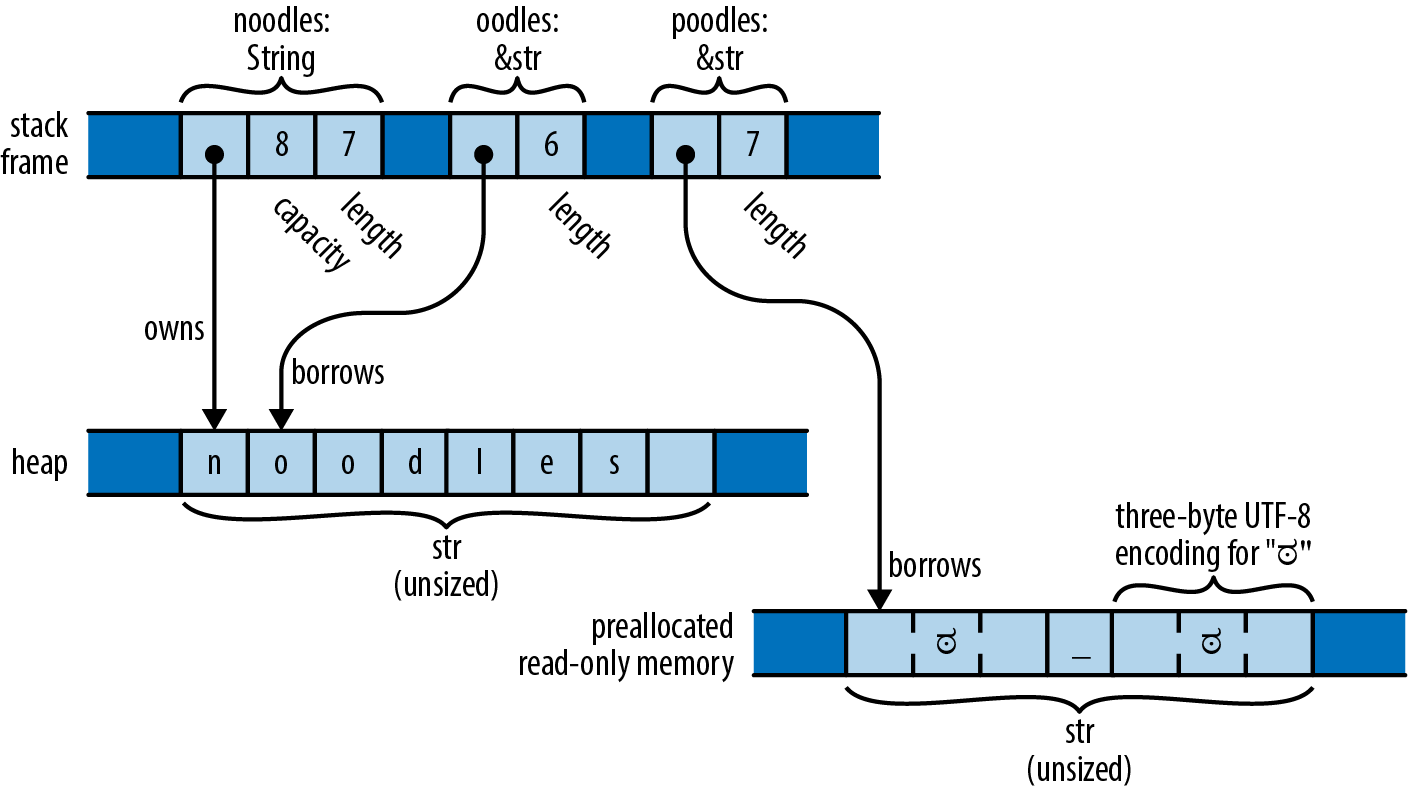
A String has a resizable buffer holding UTF-8 text. The buffer is allocated on the heap, so it can resize its buffer as needed or requested. You can think of a String as a Vec<u8> that is guaranteed to hold well-formed UTF-8; in fact, this is how String is implemented.
The str type, also called a ‘string slice’, is the most primitive string type. It is usually seen in its borrowed form, &str.
A &str (pronounced “stir” or “string slice”) is a reference to a run of UTF-8 text owned by someone else: it “borrows” the text. Like other slice references, a &str is a fat pointer, containing both the address of the actual data and its length. You can think of a &str as being nothing more than a &[u8] that is guaranteed to hold well-formed UTF-8.
A string literal is a &str that refers to preallocated text, typically stored in read-only memory (in the executable) along with the program’s machine code. poodles is a string literal, pointing to seven bytes that are created when the program begins execution and that last until it exits.
A String or &str’s .len() method returns its length. The length is measured in bytes, not characters.
| |
It is impossible to modify a &str.
| |
&str和&mut str对应&[T]和&mut [T]。
For creating new strings at run time, use String type.
The type &mut str does exist, but it is not very useful, since almost any operation on UTF-8 can change its overall byte length, and a slice cannot reallocate its referent. In fact, the only operations available on &mut str are make_ascii_uppercase and make_ascii_lowercase, which modify the text in place and affect only single-byte characters, by definition.
- 长度变了,胖指针也变了。
String
&str is very much like &[T]: a fat pointer to some data. String is analogous to Vec<T>.
Like a Vec, each String has its own heap-allocated buffer that isn’t shared with any other String. When a String variable goes out of scope, the buffer is automatically freed, unless the String was moved.
There are several ways to create Strings:
The
.to_string()method converts a&strto aString. This copies the string.1let error_message = "too many pets".to_string();- The
.to_owned()method does the same thing, and you may see it used the same way. It works for some other types as well.
- The
The
format!()macro works just likeprintln!(), except that it returns a newStringinstead of writing text tostdout, and it doesn’t automatically add a newline at the end.1 2assert_eq!(format!("{}°{:02}′{:02}″N", 24, 5, 23), "24°05′23″N".to_string());Arrays, slices, and vectors of strings have two methods,
.concat()and.join(sep), that form a newStringfrom many strings.1 2 3let bits = vec!["veni", "vidi", "vici"]; assert_eq!(bits.concat(), "venividivici"); assert_eq!(bits.join(", "), "veni, vidi, vici");
A &str can refer to any slice of any string, whether it is a string literal (stored in the executable) or a String (allocated and freed at run time). This means that &str is more appropriate for function arguments when the caller should be allowed to pass either kind of string.
Using Strings
Strings support the == and != operators. Two strings are equal if they contain the same characters in the same order (regardless of whether they point to the same location in memory). Strings also support the comparison operators <, <=, >, and >=, as well as many useful methods and functions.
| |
- Given the nature of Unicode, simple
char-by-charcomparison does not always give the expected answers. The Rust strings"th\u{e9}"and"the\u{301}"are both valid Unicode representations for thé, the French word for tea. Unicode says they should both be displayed and processed in the same way, but Rust treats them as two completely distinct strings. - Similarly, Rust’s ordering operators like
<use a simple lexicographical order based on character code point values. This ordering only sometimes resembles the ordering used for text in the user’s language and culture.
Other String-Like Types
Rust guarantees that strings are valid UTF-8. Sometimes a program really needs to be able to deal with strings that are not valid Unicode. This usually happens when a Rust program has to interoperate with some other system that doesn’t enforce any such rules.
Rust offers a few string-like types for these situations:
- Stick to
Stringand&strfor Unicode text. - When working with filenames, use
std::path::PathBufand&Pathinstead. - When working with binary data that isn’t UTF-8 encoded at all, use
Vec<u8>and&[u8]. - When working with environment variable names and command-line arguments in the native form presented by the operating system, use
OsStringand&OsStr. - When interoperating with C libraries that use null-terminated strings, use
std::ffi::CStringand&CStr.
Type Aliases
The type keyword can be used like typedef in C++ to declare a new name for an existing type:
| |
- The type
Byteshere is shorthand for this particular kind ofVec.
Beyond the Basics
Rust’s user-defined types give the language much of its flavor, because that’s where methods are defined. There are 3 kinds of user-defined types: structs, enums, and traits. Functions and closures have their own types.
References
- Programming Rust, 2nd Edition (Covers the Rust 2021 Edition)
- https://www.gnu.org/software/guile/manual/html_node/Reals-and-Rationals.html
- https://www.freecodecamp.org/news/what-is-a-rational-number-definition-and-rational-number-example/
- https://doc.rust-lang.org/std/primitive.str.html
- https://doc.rust-lang.org/book/ch04-01-what-is-ownership.html#the-stack-and-the-heap